PDF Text Extractor - Extract PDF Text with OCR Spesifikasjoner
|
PDF Text Extractor er et verktøy utviklet for å trekke ut tekst fra PDF-filer med ORC og skannede bilder til redigerbar tekst

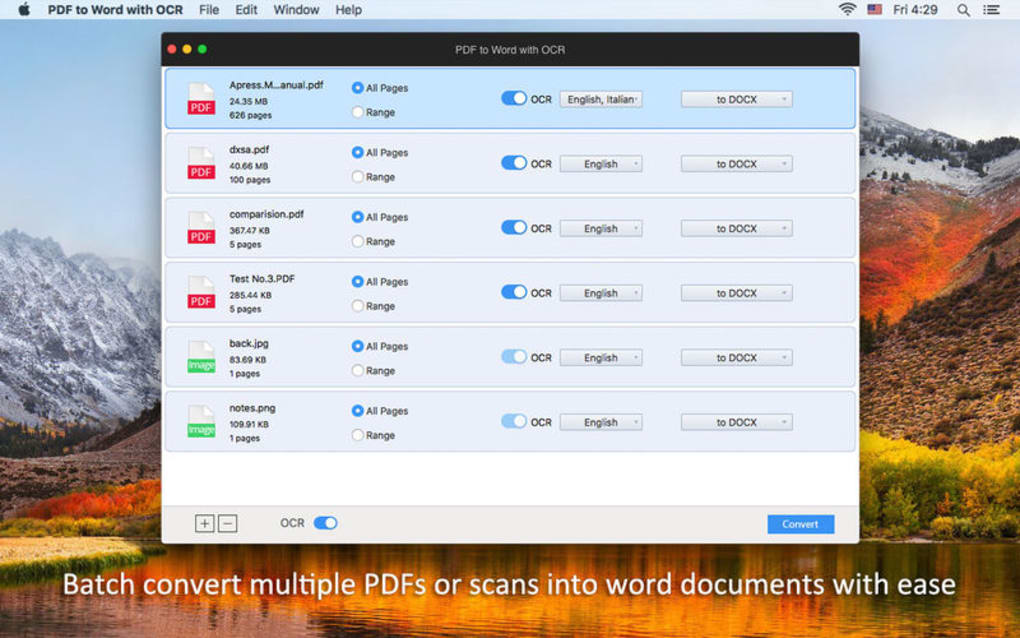
PDF Text Extractor er et verktøy utviklet for å trekke ut tekst fra PDF-filer med ORC og skannede bilder til redigerbar tekst. PDF Text Extractor kan hjelpe deg med å gjenkjenne tekst og tegn fra dokumentbilder. PDF Text Extractor støtter 40 gjenkjennelsesspråk. Du kan redigere den behandlede teksten i et Word-dokument eller annen dokumentredigerer.
Nøkkelegenskaper:
Konverter tekstinnhold til redigerbar tekst.
Med PDF Text Extractor kan du enkelt få og bruke tekstinformasjonen til pdf-dokument.
OCR-funksjon
Når du får skannet dokument og lagrer det som pdf-fil, kan du bruke PDF Text Extractors OCR-funksjon til å gjenkjenne tekstinnholdet;
Previewer for MultiMarkdown, Markdown, tekst og HTML-filer; oppdaterer forhåndsvisning helst filen er lagret.
PDF OCR X Community Edition er et enkelt drag-og-slipp-verktøy som konverterer dine enkeltsidede PDF-filer og bilder til tekstdokumenter eller søkbare ..
PDF-OCR-Free er en enkel dra-og-slipp-app som konverterer PDF-filene dine til søkbare PDF-filer
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|