PDF Text Extractor - Extract PDF Text with OCR Technische Daten
|
PDF Text Extractor ist ein Dienstprogramm zum Extrahieren von Text aus PDF-Dateien mit ORC und gescannten Bildern in bearbeitbaren Text

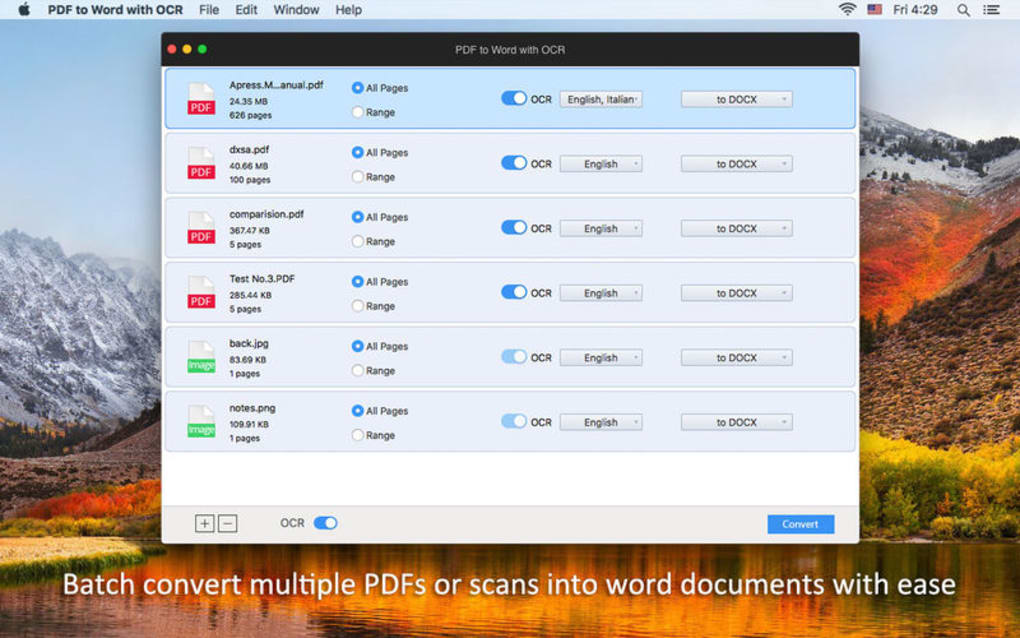
PDF Text Extractor ist ein Dienstprogramm zum Extrahieren von Text aus PDF-Dateien mit ORC und gescannten Bildern in bearbeitbaren Text. PDF Text Extractor kann Ihnen helfen, Text und Zeichen aus Dokumentenbildern leicht zu erkennen. PDF Text Extractor unterstützt 40 Erkennungssprachen. Sie können den verarbeiteten Text in einem Word-Dokument oder einem anderen Dokumenteditor bearbeiten.
Hauptmerkmale:
Konvertieren Sie Bildtextinhalte in bearbeitbaren Text.
Mit PDF Text Extractor können Sie auf einfache Weise die Textinformationen eines PDF-Bilddokuments abrufen und verwenden.
OCR-Funktion
Wenn Sie ein gescanntes Dokument als PDF-Datei speichern, können Sie die OCR-Funktion von PDF Text Extractors verwenden, um den Textinhalt zu erkennen.
Previewer für Multimark, Markdown, Text und HTML-Dateien; aktualisiert die Vorschau jederzeit die Datei gespeichert wird.
PDF OCR X Community Edition ist ein einfaches Hilfsprogramm zum Ziehen und Ablegen, mit dem Sie einseitige PDFs und Bilder in Textdokumente oder durchsuchbare ..
PDF-OCR-Free ist eine einfache Drag-and-Drop-App, die Ihre PDFs in durchsuchbare PDF-Dateien umwandelt
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|