PDF-to-HTML-Free 仕様
|
PDF-to-HTML-Freeは、元のテキスト、画像を使用して、PDF(スキャンおよび暗号化されたPDFを含む)ファイルを迅速かつ効率的にHTMLに変換できます
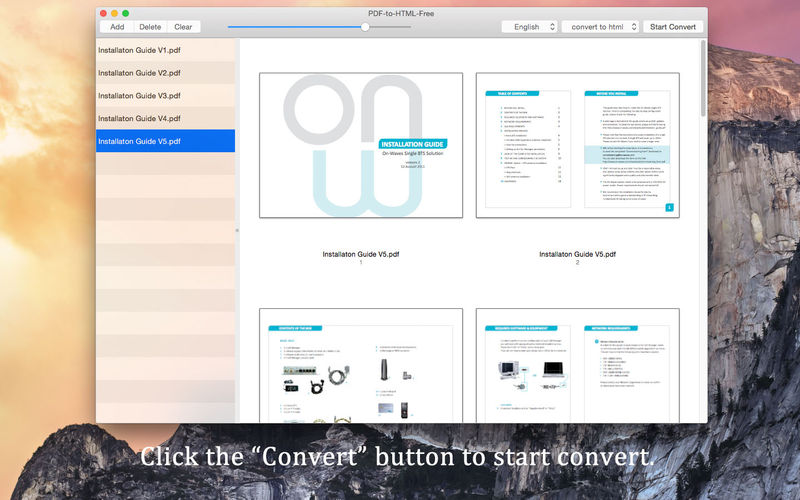
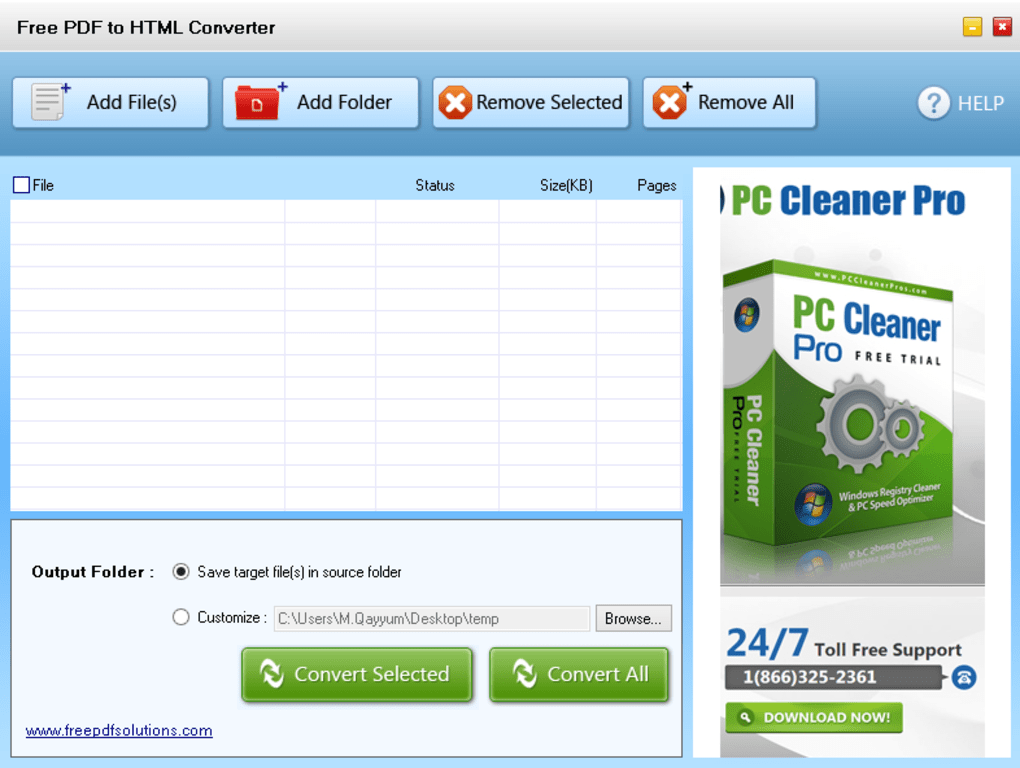
PDF-to-HTML-Freeは、元のテキスト、画像、グラフィック、およびハイパーリンクを大幅に保存したまま、PDF(スキャンおよび暗号化されたPDFを含む)ファイルをHTMLにすばやく効率的に変換できます。変換後、出力HTMLは元のPDFファイルとまったく同じように見えます。
============ OCRテクノロジー============
* OCR(光学文字認識)を使用してPDFをHTMLファイルに変換します。
45の認識言語をサポート:英語、ドイツ語、フランス語、イタリア語、ポルトガル語、スペイン語など
============高度な保存=============
*出力HTMLドキュメント内の元のPDFテキスト、レイアウト、画像、グラフィック、表、ハイパーリンクを正確に保持します。
============バッチおよび部分変換============
*バッチ変換では、複数のPDFファイルを一度にインポートできるため、時間を節約できます。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|