PDF & Image Text Extractor 仕様
|
OCRでPDFや画像からテキストを抽出する..
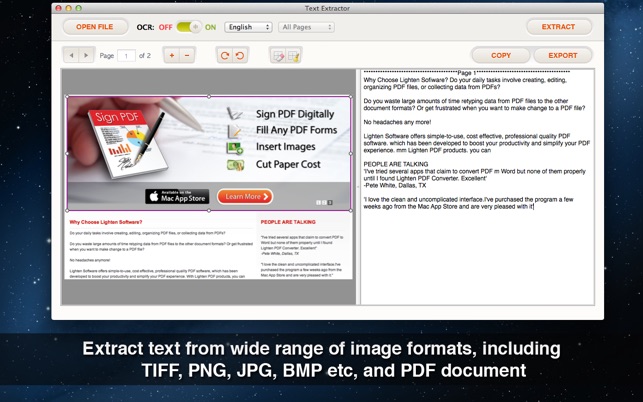
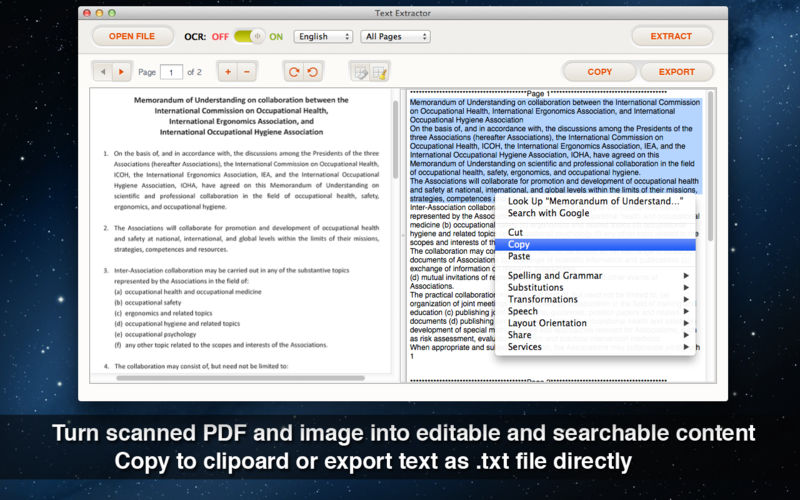
OCRを使ってPDFや画像からテキストを抽出する
PDFおよびImage Text Extractorは、すべてのPDFファイル、スキャンされたPDF文書、デジタル画像を.txtファイルとして保存するのに役立つソフトウェアの一種です。さらに、手動で、画像からテキストを正確に認識し、コンテンツを効率的に抽出することができます。それが私たちの高度な光学式文字認識(OCR)技術です。
機能と用途を強調する:
PDFファイル、スキャンしたPDFファイル、または画像ファイルをTXTファイルに変換して、内容を簡単に取得できるようにしてから、必要に応じて情報を使用または編集できます。 OCRの主な特徴はテキスト認識です。元のファイルが高品質の場合、認識率も高くなります。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|